I am primarily interested in designing and implementing pattern recognition approaches for computer vision applications that are embowered by machine learning frameworks.
Object Recognition
The process of finding objects-targets in an image constitutes on of the most challenging tasks in computer vision. My work focuses on the combination of scale invariant detectors and descriptors with well organized vocabulary trees in order to accomplish demanding recognition tasks. This video demonstrates my first work on real-time object recognition. After constructing a database containing several images from different objects, SIFT was utilized to provide stable features, whilst the whole process is based on the OpenCV framework.
Feature Extraction
The efficiency of a pattern recognition technique mainly imposes upon its ability to decode visual information in cluttered environments. To this end, researchers emphasized in creating recognition schemes based on appearance features with local estate. Algorithms of this field extract features with local extent that are invariant to possible illumination, viewpoint, rotation and scale changes.
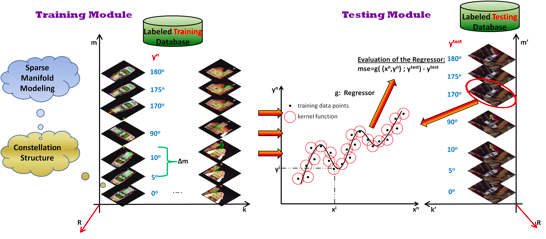
Manifold Modeling for 3D Object Pose Estimation
Following the intuition that different objects observed from similar viewpoints share identical poses, we designed and implemented a novel approach that incorporates a robust constellation structure and sparse manifold modeling for 3D object pose recovering. Our work is highly motivated by the remarkable skills exhibited by humans in the particular task of finding the relative pose of objects given an initial hypothesis. We treat the constellation structure problem from an unsupervised learning perspective and address the manifold modeling issue as conforming an ellipse over the extracted constellation points. We then formulate it as a combinatorial optimization problem using the Particle Swarm Optimization (PSO) tool and graph analysis techniques. In learning a representative description of a 3D object pose model, our algorithm requires limited supervision during the learning process whilst resulting in a problem of reduced dimensionality.
Sparse Grasping Manifolds
The efficient manipulation of arbitrarily placed objects depends on the estimation of their 6 DoF geometrical configuration. In this paper we tackle this issue by following the intuitive idea that different objects, viewed under the same perspective, should share identical poses and, moreover, these should be efficiently projected onto a well-defined and highly distinguishable subspace. This hypothesis is formulated here by the introduction of grasping manifolds relying on a bunch-based structure that incorporates unsupervised clustering of the abstracted visual cues and encapsulates appearance and geometrical properties of the objects. The resulting grasping manifolds represent the displacements among any of the extracted bunch points and the two foci of an ellipse fitted over the members of the bunch-based structure. We post-process the established grasping manifolds via L1 norm minimization so as to build sparse and highly representative input vectors that are characterized by large discrimination capabilities. While other approaches for robot grasping build high dimensional input vectors, thus increasing the complexity of the system, our method establishes highly distinguishable manifolds of low dimensionality. This paper represents the first integrated research endeavor in formulating sparse grasping manifolds, while experimental results provide evidence of low generalization error justifying thus our theoretical claims. The following videos demonstrate the efficiency of our method for eye-in -hand (box.avi car.avi) and eye-to-hand (eth_box.avi eth_tool.avi) camera configurations.
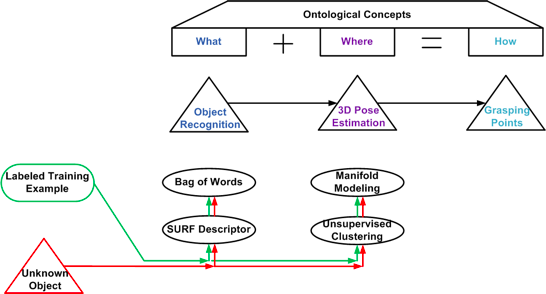
Ontology-based Object Grasping
In this paper, we aim at designing a unified architecture for autonomous manipulation of unknown objects, which is capable of answering and addressing the constraints of all the following questions: “What is the object?”, “Where is it?" and “How to grasp it?". Towards this end, we address the recognition problem from a shape-based perspective, whilst obtaining accurate detection decisions via a Bag-of-Visual Words classification scheme. Moreover, the 6 DoF pose estimation module is based on the intuitive idea that even different objects when observed under the same viewpoints should share identical poses that can be projected onto highly discriminative subspaces. Grasping points are found through an ontology-based knowledge acquisition where recognized objects inherit the grasping points assigned to the respective class. Our ontologies include: a) object-class related data, b) pose-manifolds assigned to each instance of the object-class conceptual model and c) information about the grasping points of every trained instance. The main idea underlying the proposed method is illustrated in the following figure.
Available experimental results for the cow, car and cup queries, respectively. This video demonstrates the efficiency of our method.